
No hay PLN sin lingüística
El Procesamiento de Lenguaje Natural tiene que apoyarse necesariamente en los profesionales del lenguaje, lingüistas y filólogos que desde los inicios de la Inteligencia Artificial han propuesto modelos para trabajar con él, analizarlo y extraer información. Los enfoques simbólico y estadístico con los que se trabaja en PLN actualmente deben colaborar estrechamente para generar las herramientas que nos permitirán interactuar con las máquinas utilizando el lenguaje.
Este artículo resume la charla que ofrecí el 21 de diciembre de 2017 en Google Campus (Madrid) en el encuentro de Madrid.ai 1 2. En aquel encuentro también participaron Cristina Santamarina hablando sobre desarrollo de chatbots, y Nieves Ábalos y Carlos Muñoz-Romero exponiendo los desafíos que supone dotar a una inteligencia artificial de emociones y personalidad.
Introducción
"No hay PLN sin lingüística", @jgsogo en @Madrid_City_AI pic.twitter.com/Olw37AOKV9
— Elena Álvarez Mellado (@lirondos) 21 de diciembre de 2017
Quienes me conocéis sabéis perfectamente que mantengo una cruzada personal por recuperar a los lingüistas para la tarea en la que han sido formados durante años. Me da rabia que personas con varios años de Universidad acaben haciendo un trabajo de etiquetado que, aunque necesario, no necesita su nivel de formación. Así que aprovecho cualquier oportunidad para intentar poner en valor los estudios de letras, la filología y la lingüística.
Esta charla es la continuación de otra que dí en la Facultad de Filología de la Universidad de Valladolid para estudiantes de grado y que después adapté para el colectivo de desarrolladores de CyliconValley. En aquellas charlas me centraba en las ontologías, en la primera de ellas trataba de hacer ver a los estudiantes que ellos eran necesarios para generarlas y en la segunda pretendía mostrar a los programadores cómo necesitan la ayuda de estos profesionales para hacer una ontología de calidad. Pero lo cierto es que a día de hoy los lingüistas ya están trabajando en la industria del PLN, ya hay puestos importantes cubiertos por personas cuya formación es puramente de letras, llevan equipos, toman decisiones e indican a los técnicos el enfoque que debe darse a los desarrollos. A los alumnos hay que animarles con ese tiempo futuro para que piensen que el mundo les está esperando, pero en auditorios más curtidos debemos reconocer que no hay PLN sin lingüística, ni puede haberlo, que si queremos montar un negocio que trabaje con el lenguaje debemos contar con la ayuda de un especialista.
En el mundo del PLN aún no están definidos los problemas que deben resolverse, no hay pruebas que permitan determinar si un algoritmo ha superado cierta tarea o no; el objetivo de comprender el lenguaje natural incluye una dosis de subjetividad sobre la que es complicado evaluar los avances tecnológicos. La parte más tecnológica y la industria ha echado las naves al mar y navega en busca de la solución creando gran expectación en torno a ella y quizá una sensación de hype a la que puede sucederse una decepción importante; por su parte, los investigadores aún se encuentran estudiando el detalle de los vientos y las mareas del lenguaje, proponiendo soluciones a un ritmo constante, pero mucho más pausado. Lo que está claro es que la industria en su vagar por el Océano no puede hacer otra cosa que utilizar las mareas y los vientos cuando se encuentra con ellos y, en algún momento, algún barco llegará al destino.
¿Qué entiendo por PLN?
El Procesamiento de Lenguaje Natural (PLN) es una rama de la Inteligencia Artificial que comprende problemas muy variados con
un grado de madurez muy diferente entre ellos (esta
recopilación de Kyubyong
ofrece un listado bastante completo), aunque cuando
yo hablo de PLN quiero referirme al conjunto de herramientas, algoritmos, modelos,... que me permiten convertir un texto expresado
correctamente en lenguaje natural en un conjunto de datos que pueden ser procesados por un algoritmo. Desde mi punto de vista es la
tarea más dependiente del PLN y, en consecuencia, una de las más difíciles de productivizar en un entorno industrial.
Natural Language Processing Tasks and References


El algoritmo del PLN, por lo tanto, contaría con el texto plano como principal entrada de datos y adicionalmente podría recibir información contextual sobre el tono del mensaje y el contexto del hablante. Su tarea principal consistiría en convertir ese documento en datos estructurados, aunque si tenemos en cuenta Collobert et al. (2011) "Will a computer program ever be able to convert a piece of English text into a programmer friendly data structure that describes the meaning of the natural language text? Unfortunately, no consensus has emerged about the form or the existence of such a data structure" 3 debemos ser bastante pesimistas. Sin embargo, quiero creer que aquí se habla de codificar el lenguaje con todos sus matices, pero que la duda no es tal si pensamos en codificar una información más fáctica.
La carencia de un standard de codificación dificulta la aparición de empresas que se ocupen exclusivamente de esta parte del PLN (desde el texto en bruto hasta la información estructurada) y la mayoría de las empresas intentan abordar por ellas mismas el problema de extremo a extremo, es decir, desde la entrada de texto hasta la aplicación de negocio.
La lingüística en el PLN
El nacimiento de la Inteligencia Artificial estuvo muy condicionado por los trabajos en torno a la traducción automática de los años 1950s y 1960s, en esta época se seguía un enfoque puramente simbólico y basado en reglas para abordar el problema y, sin duda alguna, el papel de los lingüistas en aquella época fue muy relevante. Posteriormente la evolución de la IA confió en la potencia de cálculo de los procesadores y primó el desarrollo basado en métodos estadísticos, sin embargo, hoy en día se vuelve a mirar el enfoque simbólico y su combinación con la potencia de cálculo actual y la gran abundancia de datos disponibles.
La semántica distribucional

En 1957, en la primera etapa del PLN, el lingüista británico John Rupert Firth exponía su noción del contexto de situación según la cual el significado de una palabra podía extraerse del contexto en el que aparece: "You shall know a word by the company it keeps" 4, la aplicación de este principio está en la base de los conocidos algoritmos de word embeddings que aparecerieron hace algunos años: word2vec (Mikolov et al., 2013) y GloVe (Pennington et al., 2014). Estos algoritmos permiten extraer información semántica de texto sin anotar, simplemente calculando las probabilidades de aparición de una palabra en un contexto (o de un contexto en el entorno de una palabra).
El ejemplo de word2vec que se hizo famoso fue el que relacionaba las palabras rey y reina: king - man + woman = queen. Como
se observa en la imagen inferior, el algoritmo ha podido capturar significados semánticos a partir del texto. En uno de ellos se
codifica el cambio de rol de género (flecha roja) de tal forma que aplicado a una palabra con rol masculino nos lleva a su
correspondiente femenina, así al aplicarlo a king obtenemos queen, al hacerlo con man obtenemos woman,... La otra relación
que se observa en la imagen codifica el incremento de autoridad o realeza (flecha verda), así aplicando este vector a man obtenemos
king, haciéndolo sobre woman llegamos a queen y cabe esperar que si lo aplicáramos sobre la palabra kid nos conduciría
a princeps.
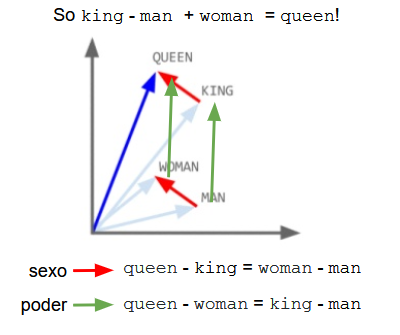
Esto es bastante sorprendente, a partir de texto tal cual, tenemos un algoritmo capaz de extraer información semántica sin necesidad de decirle nada, sin necesidad de etiquetar el texto. Sin embargo, también tiene otros inconvenientes:
- El tiempo y la cantidad de datos necesarios para su entrenamiento.
- La interpretabilidad: las palabras se codifican en vectores de números reales en los que se ha perdido toda referencia al dato original del lenguaje, por lo tanto no sabremos qué hemos de tocar si queremos evitar (o premiar) ciertos comportamientos del modelo.
- Ética: al apartarnos del dato en crudo se pierde la perspectiva de los posibles sesgos que hayan aparecido como consecuencia de la elección de unos datos de entrada.
- Cómo aplicar estos algoritmos a la comprensión del lenguaje, resolución de inferencias, preguntas complejas.
El filólogo estructurado
Ya en los orígenes del Procesamiento de Lenguaje Natural surgió la preocupación por la representación del lenguaje en estructuras formales que permitieran trabajar con él y una de las más relevantes fue la representanción a través de grafos que está en el origen de los tesauros y las ontologías.
Un ontología no es más que la formalización del conocimiento sobre el mundo en conceptos y relaciones entre ellos de una forma no ambigua, explícita y compartida. Así las ontologías generalmente están formadas por un tesauro (una jerarquía de conceptos según sus relaciones de hiperonimia e hiponimia) y un amplio conjunto de relaciones entre ellas. En principio cualquier ontología suficientemente explícita sobre un dominio de conocimiento es capaz de codificar cualquier información relativa al mismo.
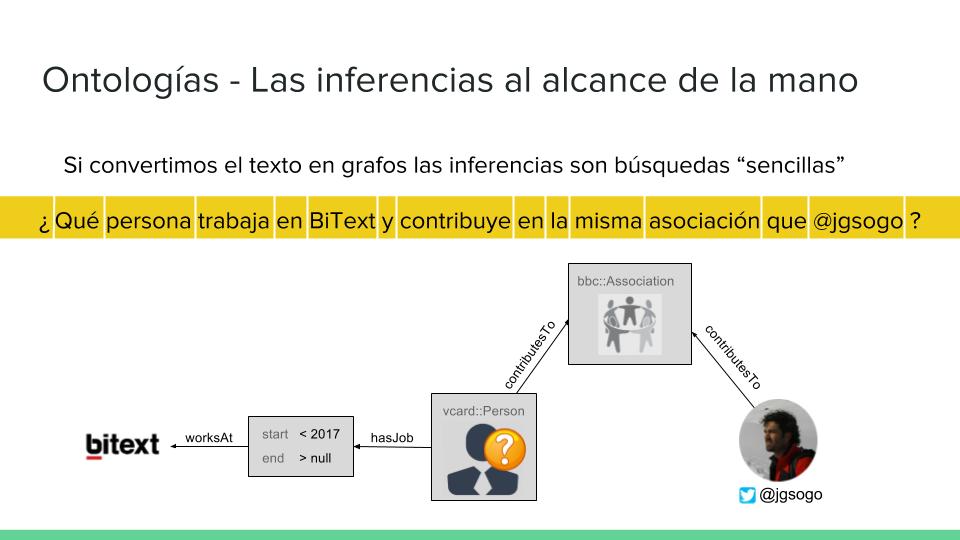
Si incluímos en el pipeline convencional (tokeninazión, pos-tagging, lematización, NER,...) la conversión de la oración a su grafo ontológico, podríamos codificar la información de un texto en forma de grafo, así la respuesta a preguntas complejas no sería más que la búsqueda en el grafo de un nodo y otros problemas como inferencias, resumen,... se reducirían a operaciones sobre grafos ampliamente documentadas en la literatura.
El problema principal de las ontologías no es ya su coste de generación puesto que requiere de la participación de un especialista del lenguaje, sino el coste prohibitivo que supone mantenerlas actualizadas (el lenguaje evoluciona continuamente, incorpora nuevas palabras, cambia significados, usos,...). Sin embargo son una de las herramientas más potentes para trabajar en la resolución de las ambigüedades que aparecen en cada etapa del PLN.
Conclusión
Desde mi punto de vista el futuro del PLN necesita de las contribuciones de ambos campos, del enfoque simbólico y del estadístico. De la conjunción de ambos saldrán las aplicaciones que triunfarán en el futuro próximo, aquella empresa que cuente entre sus trabajadores con filólogos y recursos lingüísticos posee una ventaja competitiva fundamental frente a las que sólo confían en los algoritmos, el big data y la potencia de cálculo. Un enfoque como el siguiente tendría muchas probabilidades de éxito:
- Centrarse en un único dominio (domótica, legal, restaurantes,...), problema e idioma.
- Construir una ontología básica de partida.
- Utilizar embeddings y otros algoritmos para mantener la ontología y añadir nuevos términos.
- Generar un corpus de preguntas para entrenar.
- Programar el pipeline de PLN.
- Diseñar el algoritmo de generación de grafos a partir de oraciones.
- Construir el motor de inferencias.
Este enfoque industrial también deberá estar muy pendiente de los principales problemas que hoy ocupan a la investigación en Inteligencia Artificial y cuyas soluciones deberán ser incorporadas cuanto antes a cualquier solución comercial:
- Módulo de lenguaje controlado: cómo normativizar los textos para que nuestro algoritmo de comprensión no tenga que preocuparse por idiolectos singulares o de grupo.
- Interpretabilidad: el comportamiento de seguir las directrices de la empresa, debemos saber qué parámetros hay que tocar para evitar comportamientos indeseados.
- Ética: trabajar sobre los sesgos, originados como consecuencia de los datos de partida, del proceso de entrenamiento o de programación del propio algoritmo.
- Legalidad: hay que tener en cuenta que “[Salvo consentimiento explícito o autorización legal específicos,] todo interesado tendrá derecho a no ser objeto de una decisión basada únicamente en el tratamiento automatizado, incluida la elaboración de perfiles, que produzca efectos jurídicos en él o le afecte significativamente de modo similar” 5.
El Procesamiento de Lenguaje Natural es un campo de investigación y de aplicación práctica de rabiosa actualidad. La industria hoy comete el error de querer ir más rápido que la tecnología y la investigación con el ánimo de aprovechar las expectativas generadas por la ciencia ficción en las películas, así genera un hype con poco fundamento y es posible que en los próximo años se disipe parte de todo este humo y sintamos la decepción de enfrentarnos a la realidad de lo que se ha conseguido hasta ahora. Esta decepción desplazará los recursos hacia otras áreas de la IA más atractivas, pero de la mano de la investigación, de los lingüistas y de los desarrolladores preocupados por el origen de los datos, seguiremos avanzando con paso firme en la exploración de este mundo apasionante.

Notas y materiales
- Puedes descargarte la presentación correspondiente a la charla aquí.
- Mira algunas de las fotos del evento en Flickr
- Convocatoria en Meetup: https://www.meetup.com/es-ES/MADRID-AI/events/245802179/↩
- Reseña en Planeta Chatbot: https://planetachatbot.com/madrid-city-ai-chatbots-y-emociones-a57836487b14↩
- Collobert et al., 2011. Natural Language Processing (Almost) from Scratch. Journal of Machine Learning Research 12 (2011) 2493-2537. Download.↩
- Citado en: Kenneth Church (2007). A Pendulum Swung too Far. Linguistic Issues in Language Technology 6 (4): 5.↩
- Reglamento (UE) 2016/679 de Protección de Datos Personales.↩