
Mejorar la corrección de textos producidos por OCR
El lunes pasado Leticia planteaba si es posible mejorar la corrección automática de un texto producido por OCR, y recapitulaba algunas de las dificultades que se había encontrado con más frecuencia. Yo quiero dividirlas en dos categorías diferentes: las debidas al proceso de reconocimiento del OCR y las que están relacionadas con las sugerencias de corrección.
Errores de reconocimiento de caracteres
El OCR (Reconocimiento Óptico de Caracteres) es un proceso de identificación automática de los caracteres contenidos en una imagen que se plantea como un problema de reconocimiento de patrones (las propias letras). En la bibliografía se considera un problema prácticamente resuelto que ofrece gran precisión cuando está entrenado adecuadamente; no obstante siempre hay algún error relacionado con la calidad de la imagen original que provoca una identificación incorrecta de algunas letras.
Leticia muestra algunos ejemplos de este problema que reproduzco en dos imágenes a continuación. En el primer caso la interpretación incorrecta de una cadena de caracteres en favor de una única letra visualmente muy semejante:
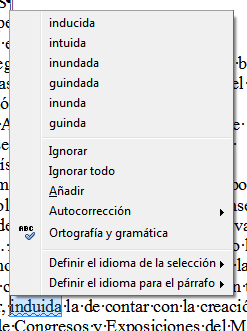
En esta segunda imagen el OCR junta dos palabras en una, otro error relativamente habitual como consecuencia de los diferentes espaciados entre las letras (kerning) y entre palabras.
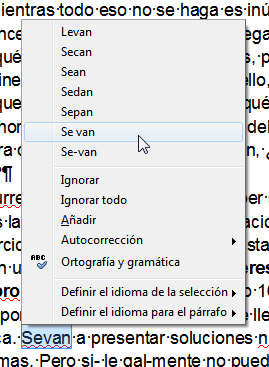
Sin embargo estos no son los problemas de los que quería hablar aquí.
Errores asociados a las sugerencias
Mucho más interesante me parece el segundo grupo de problemas, los relacionados con las sugerencias que ofrece el editor de texto que utiliza (¿Microsoft Word?). Leticia ha reunido algunas características recurrentes:
- No tiene en cuenta secuencias de caracteres muy parecidas a la hora de ofrecer sugerencias.
- No ordena las sugerencias por frecuencia de uso.
- Nada de separar más de dos palabras que han quedado juntas.
- Los guiones.
Ideas (first round)
Creo que los que están relacionados con las sugerencias se pueden abordar desde la lingüística computacional con aproximaciones relativamente sencillas: una vez que se ha identificado una palabra mal deletreada (dejemos que sea el corrector profesional el que identifique palabras fuera de sitio) tenemos que crear un sistema que ofrezca sugerencias.
Creo que se pueden combinar dos aproximaciones para construir este listado de sugerencias:
-
distancia entre palabras: un índice de tipo Jaccard letra a letra o, mejor aún, en grupos de dos/tres letras puede darnos una idea de qué palabras están más próximas a qué otras. Construir una base de datos con esta información podría resolver nuestro problema prácticamente por si solo, pero tengo dudas sobre la explosión combinatoria a la que se enfrentaría una búsqueda de este tipo o la forma de construir índices y el almacenamiento (¿estás pensando en buckets? ¿Cómo lo harías?).
-
concordancia (ahora dudo si se llama así): estamos hablando de palabras incorrectas, pero tenemos su contexto, ¡aprovechémoslo! Podemos construir una matriz de concordancia restringinda a bi-gramas de algún corpus que tengamos y, a través de esta matriz podemos obtener un primer conjunto de candidatos ordenado por frecuencia de uso.
Los dos planteamientos anteriores pueden combinarse fácilmente para obtener un listado de sugerencias ordenadas por proximidad a la palabra que está mal escrita y por frecuencia de uso. Si además incluímos un parseador morfológico podemos identificar la categoría gramatical de la palabra incorrecta para filtrar las sugerencias.
¿Qué os parece? ¿Seguimos con ello? ¿Se os ocurre alguna otra idea? ¿Creéis que sería útil algo así? Quien recoja el guante que se pronuncie en los comentarios...